Insta
Internet Outage: Why Major Websites Were Down Last Night
Sanjana Donkar
Mar 01, 2017, 05:55 PM | Updated 05:55 PM IST
Save & read from anywhere!
Bookmark stories for easy access on any device or the Swarajya app.


Last night (28 February), several websites failed to function optimally. While many may have cursed their service providers for the slowdown, the websites claim someone else was to blame.
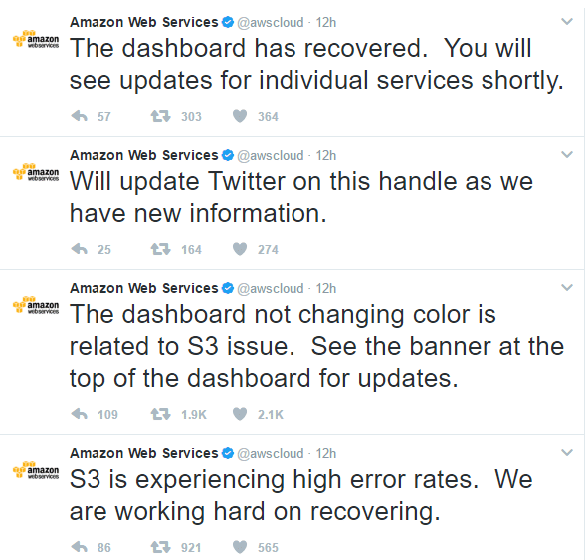
It was learnt that Amazon’s S3, a web-based storage service, faced problems, causing an internet shutdown of sorts in the east coast of the United States. Subsequently, prominent websites like Quora, Imgur, Slack, Yahoo! Mail and Medium either went offline, didn’t load images or ran slow. Amazon couldn't even update its website’s status dashboard: its red warning icons were non-functional as they were hosted on the side of the cloud that had conked out.
Amazon Web Services (AWS) hosts images for many websites, in addition to entire websites. The ‘cloud’ is made up of thousands of powerful computer servers, stored by Amazon and other players in massive server farms. The companies build and maintain these farms so that smaller players don’t have to invest in this infrastructure. According to SimilarTech, 150,714 websites rely on the services of AWS for cloud storage, and about 123,809 unique domains depend on AWS. Close to 0.8 per cent of the top one million websites use the services. Though the number is less compared to CloudFlare, which is used by 6.2 per cent of the top one million sites globally, the extent of havoc it caused was evident.
While Amazon has been rated as one of the best providers of cloud services, a shutdown resulted in the slowing down of a significant section of the internet. Amazon refused to acknowledge the shutdown as an outage and instead called it “high-error rate”. Ironically, outage-monitoring websites DownDetector and isitdownrightnow.com were also offline. An outage refers to the period when an “entire system” fails to provide or perform its primary function. On the other hand, a high-error rate refers to the repeated failure of a specific component of a system. In the case of Amazon, despite denial, the entire system failed.
Amazon has revealed no clear reason for the five-hour disruption of services, though their tweet confirms they have identified the issue. Ironically, even the status indicators on the AWS service status page rely on S3 for the storage of its health marker graphics, the reason why AWS said all services were “working” despite contrary evidence.
Amazon provided an update about the issue to its users on Twitter.
The case highlights how reliant the internet has become on several players, including Amazon, CloudFlare and Google, who provide the expensive centralised infrastructure on which the web runs.
Sanjana is a staff writer at Swarajya.
Get Swarajya in your inbox.
Magazine





